If you’ve researched “MCP token efficiency,” you’ve read some version of the same finding: MCP costs you tokens. Anthropic’s engineering post on code execution with MCP shows tool definitions and intermediate results consuming context before the agent does anything. A much-shared Reddit thread measured MCP setups costing 37% more tokens. Schema-diet and tool-filtering writeups report cutting that overhead 44%, 85%, even 100×. All of it is true, and all of it measures the same thing: the input side — what tool schemas and verbose payloads cost to carry in context. We do that work on our own server too; a recent pass cut our worst list tool from 340 to 114 tokens per row.
But that’s one side of the ledger. Those measurements compare an agent with MCP tools to the same agent with leaner plumbing. They don’t ask the prior question: what does it cost an agent to get the data without domain tools — by searching the web and reading pages? For research agents, that’s where the bill actually lives.
So we measured it. Same model, same prompts, same turn budget — one arm using domain-specific MCP tools instead of web search, the other using hosted web search plus code execution. Across three SEC research tasks, the web-search arm used 10–21× more tokens, cost 10–21× more dollars, took 4–7× longer — and scored worse on every single task.
The setup
On June 12, 2026 we ran three research scenarios, three repetitions per arm, on Claude Sonnet 4.6, pricing snapshotted June 11, 2026:
- Arm A — domain MCP tools. The edgar.tools MCP server: tools like
company_filings,material_events, andfiling_sectionthat return SEC data directly, not pages that mention it. - Arm B — agentic web search. Anthropic’s hosted web search with code execution — a strong general-purpose implementation, which is exactly why we chose it. This is a comparison of general-purpose retrieval vs domain-specific tools, not a knock on any search product.
Both arms answered the same prompts under the same 8-turn cap with caching off. Answers were graded 0–10 by an LLM judge against hand-verified reference answers built from the filings themselves, and we separately computed provenance — the fraction of claims that resolve to an actual SEC source. Full methodology, judge prompts, and per-run records are on the benchmark page, which is the canonical, versioned home for these numbers.
Results: every number with its correctness beside it
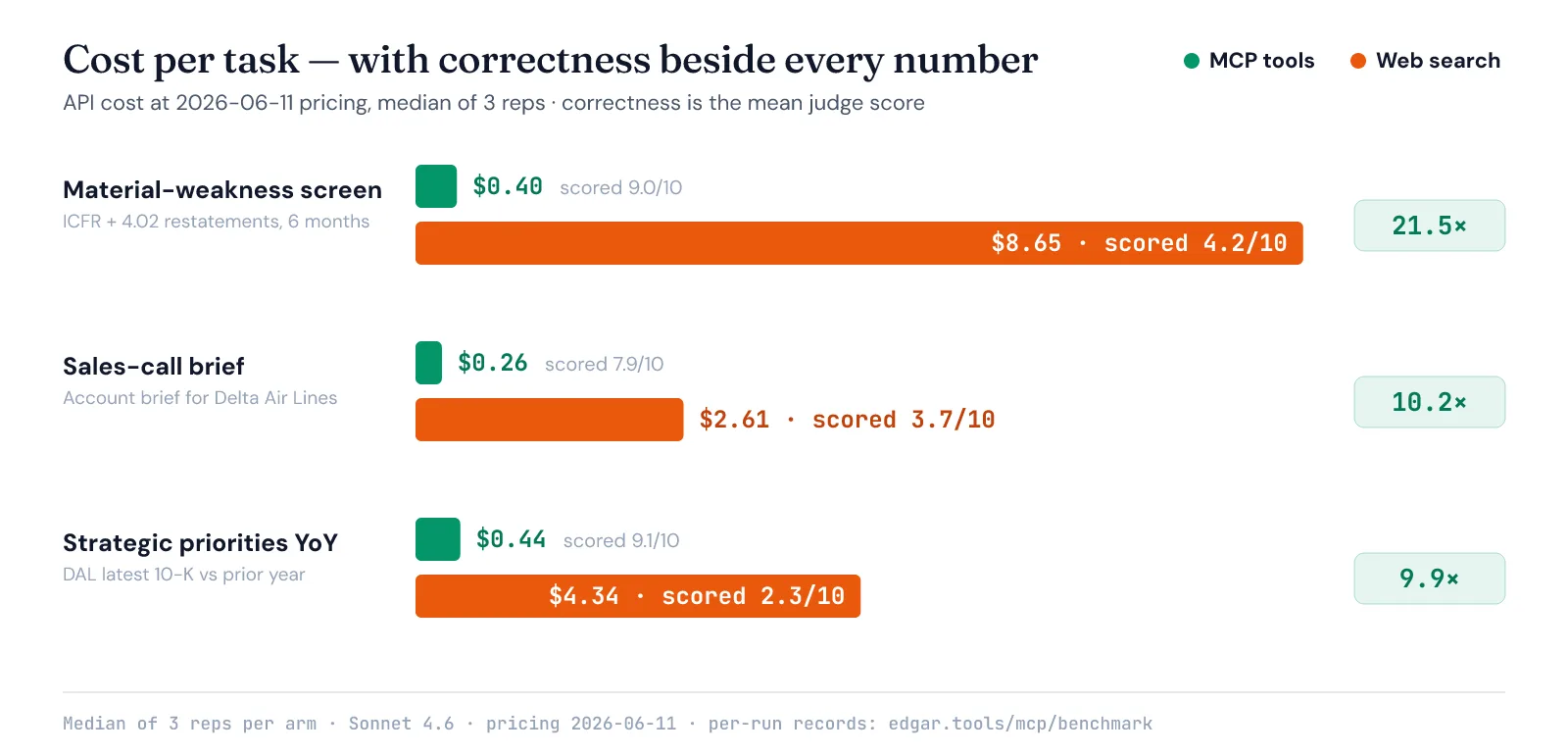
A token ratio means nothing if the cheap arm is also the sloppy arm. So here is the whole picture — medians of three runs:
| Scenario | Web ÷ MCP tokens | Web ÷ MCP cost | Web ÷ MCP latency | Correctness — MCP | Correctness — web |
|---|---|---|---|---|---|
| Screen: material weaknesses / restatements, last 6 months | 20.8× | 21.5× | 6.9× | 9.0 / 10 | 4.2 / 10 |
| Sales-call brief on Delta Air Lines | 10.0× | 10.2× | 5.1× | 7.9 / 10 | 3.7 / 10 |
| Delta’s strategic priorities, 10-K vs prior year | 10.2× | 9.9× | 4.3× | 9.1 / 10 | 2.3 / 10 |
Per-task cost, in dollars: the MCP arm ran $0.26–$0.44 per task. The web arm ran $2.61–$8.65. Web search did not win a single cell — not tokens, not cost, not latency, not correctness. The expensive arm was also the wrong arm.
Where 2.7 million tokens go
The mechanics are visible in the run traces. For the Delta sales brief, the MCP arm made 5 tool calls — an account dossier, a peer comparison, two filing analyses, a section read — ingesting about 14K tokens of tool results, roughly 70K input tokens total. The web arm made 25–30 calls in a search → scrape → re-search loop and ingested 730–910K input tokens of pages, most of which never reached the answer.
The screening task was worse: the web arm’s heaviest run made 110 calls and consumed 2.7 million input tokens to produce a 4/10 answer. Your agent pays input-token prices to read, and a web page is a wildly inefficient container for a fact. A domain tool returns the fact.
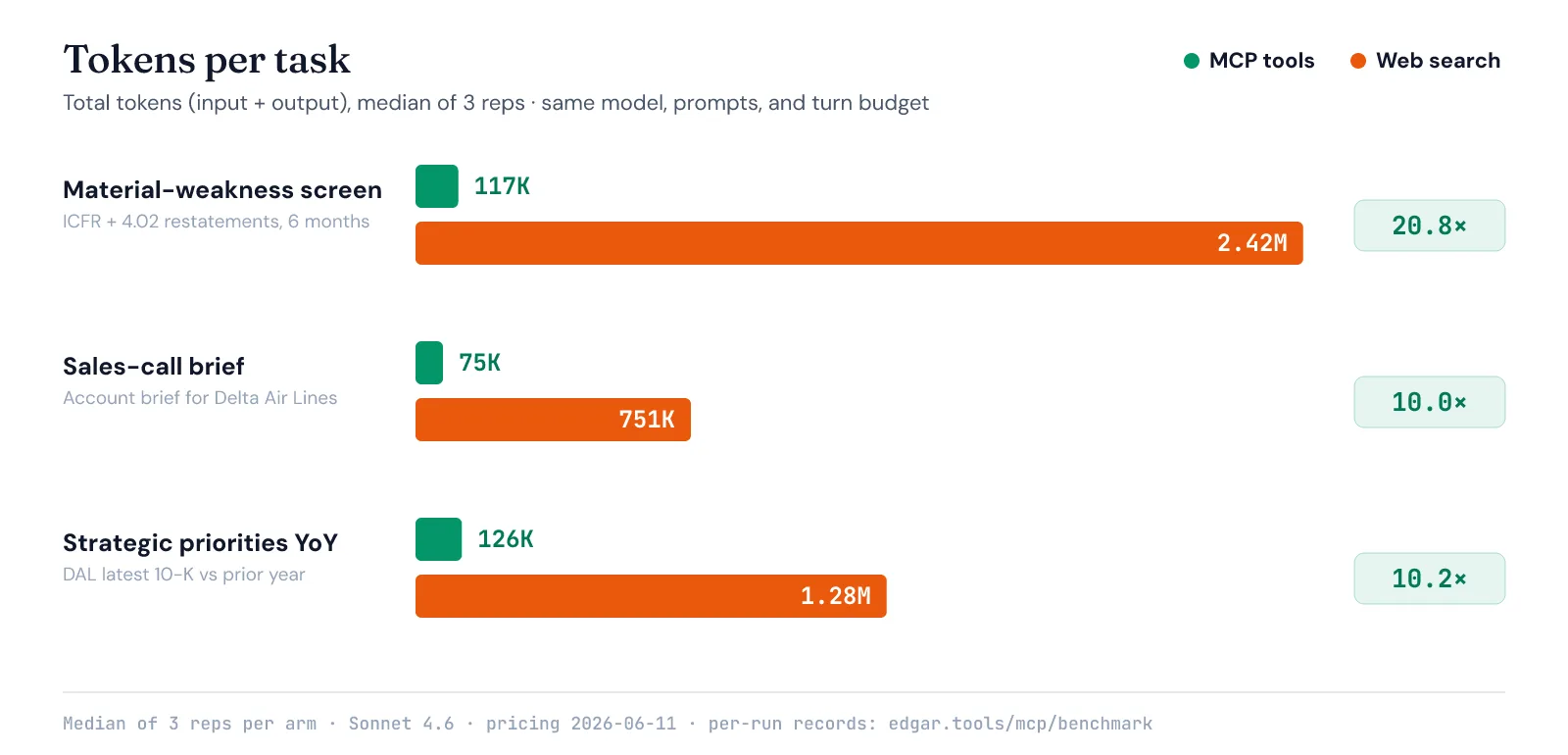
This is why the protocol-overhead debate, important as it is, misses the dominant term for research agents. Tool schemas cost you hundreds of tokens per call. Reading pages instead of data costs you hundreds of thousands per task.
The expensive arm was also the wrong arm
The token bill and the wrong answers have the same root cause: web search retrieves documents about the data, not the data.
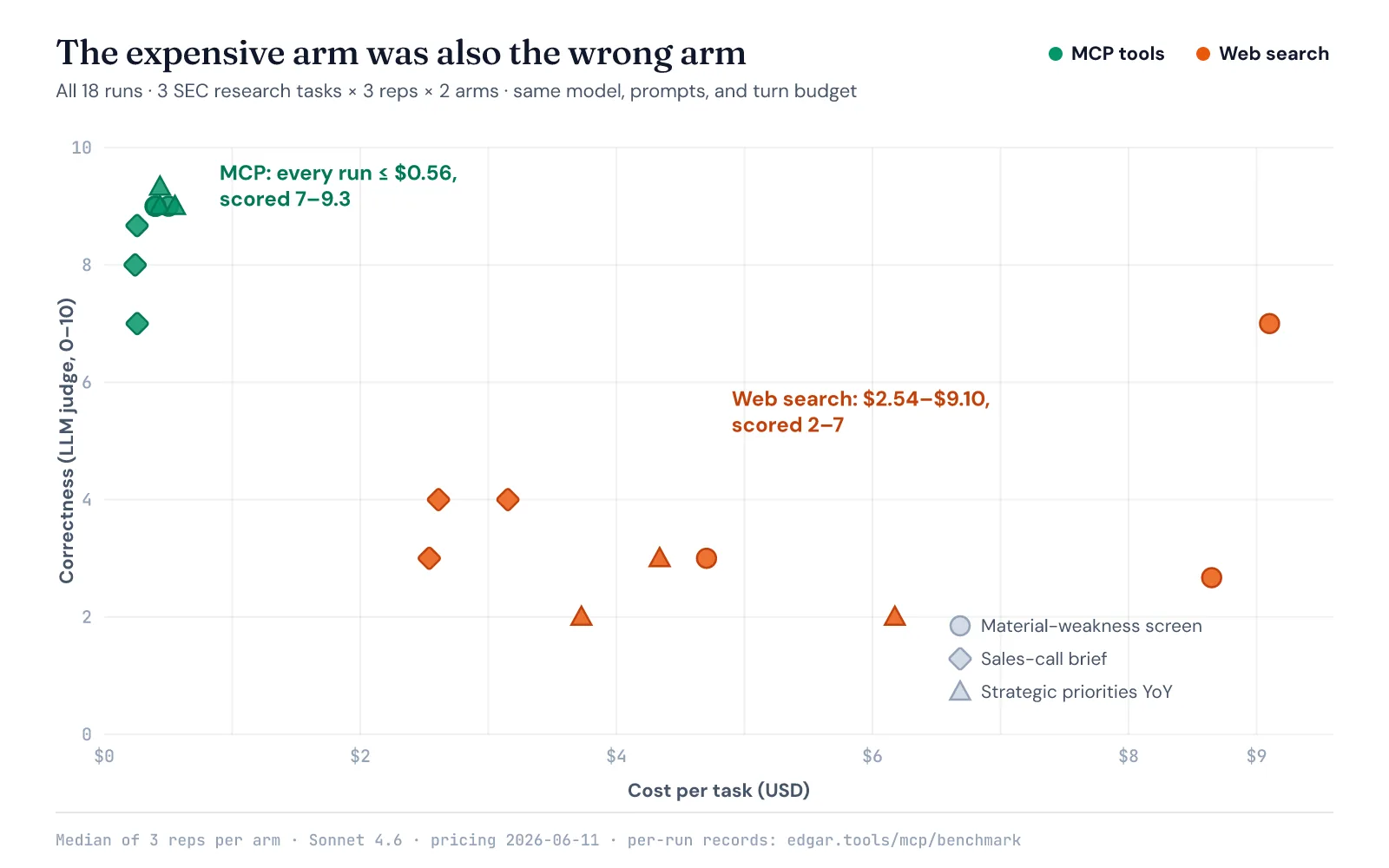
- Stale comparisons. Asked to compare Delta’s latest 10-K against the prior year, the web arm repeatedly compared FY2024 to FY2023 — with the FY2025 filing on record. The MCP arm gets the reporting period attached to every number.
- Padded screens. Asked for six months of material-weakness disclosures, the web arm padded its list with out-of-window cases, because articles about restatements don’t carry a date filter.
- Citing coverage instead of filings. On the 10-K comparison task, the web arm’s provenance was 0%, 0%, and 7% across its three runs — it quoted news about the filing, not the filing. The MCP arm cites accession numbers.
We’re publishing a fuller failure-mode taxonomy, with the receipts, as a follow-up post.
Both sides of the ledger
So is MCP a token tax or a token saving? Both, on different sides of the ledger — and the fixes compose:
- Input side (what tools cost to carry): the overhead the existing literature measures is real. Diet your schemas, filter your tools, consider code execution for orchestration-heavy work. We run this discipline on our own server — measured per-tool token footprints, trims, and budget ceilings that ratchet down as tools get leaner.
- Output side (what retrieval costs to read): for research tasks over a structured corpus, this term dominates by an order of magnitude. Domain-specific MCP tools instead of web search cut it 10–21× in our measurements — while improving the answers, because the data arrives with its dates and sources attached.
An agent with dieted domain tools wins on both sides. An agent with lean schemas that still does its research through a search box has optimized the small number.
Scope, stated plainly
These numbers are for SEC and financial-filings research on the three scenarios above — not a universal law. Web search remains the right tool for breaking news, post-publication commentary, analyst opinion, and any domain without a structured corpus and a domain server. The two compose: domain tools for the facts, web search for the context around them. (For the decision framework, see MCP vs web search: which does your AI agent actually need?.)
We’re hardening the benchmark before making any broader claim: a second model, plus a web-favoring, breaking-news-shaped scenario — and we’ll publish those results whichever way they go. Every number above carries its date and pricing snapshot, and every run’s full trace is public.
The canonical benchmark, with per-run records, judge prompts, and methodology: edgar.tools/mcp/benchmark. Or run the domain-tools arm under your own questions — install the edgar.tools MCP server and ask for something a press release wouldn’t carry.
Dwight Gunning is the creator of edgartools, the open-source Python library for SEC data, and builds edgar.tools. Benchmark run June 12, 2026: 3 scenarios × 3 repetitions × 2 arms on Claude Sonnet 4.6, pricing as of June 11, 2026; the web arm used Anthropic’s hosted web search + code execution. Full data at the link above.